Pilot 是 Istio 中一个重要的组件,它主要分为 Agent 和 Discovery Services 两部分。本文着重介绍负责注册信息和配置信息管理的 Discovery Service.
主要功能
- Istio 控制面信息监控与处理
- 服务注册信息监控与处理
- Envoy控制面信息服务:XDS Server

Config Controller
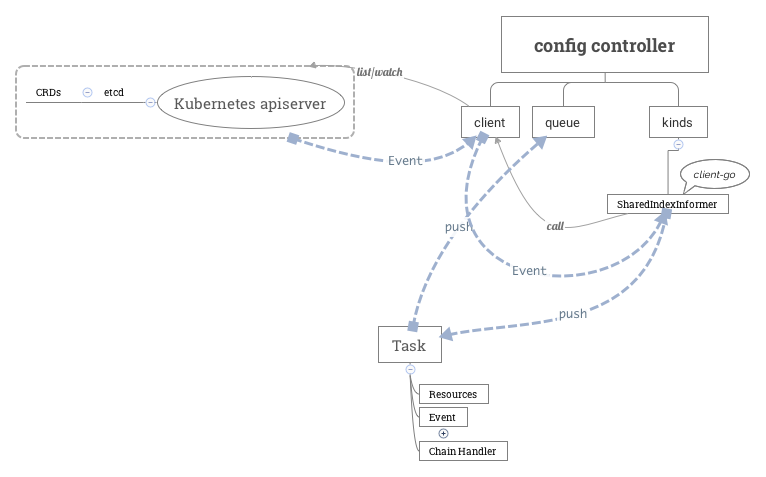
config controller包含以下3个部分:
client
client是一个rest client集合,用于连接Kubernetes apiserver,实现对istio CRD资源的 list/watch。具体而言,为每个CRD资源的group version (如config.istio.io/v1alpha2、networking.istio.io/v1alpha3)创建一个rest client。该rest client里包含了连接Kubernetes apiserver需要用到的apimachinary、client-go等库里的对象,如GroupVersion、RESTClient等。
queue
用于缓存istio CRD资源对象(如virtual-service、route-rule等)的Add、Update、Delete事件的队列,等待后续由config controller处理。详见本文后续描述
kinds
为每种CRD资源(如virtual-service、route-rule等)创建一个用于list/watch的SharedIndexInformer(Kubernetes client-go库里的概念)。
主循环
config controller主循环主要包括两方面:
- 利用client-go库里的SharedIndexInformer实现对CRD资源的 list/watch,为每种CRD资源的Add、Update、Delete事件创建处理统一的流程框架。 这个流程将Add、Update、Delete事件涉及到的CRD资源对象封装为一个 Task 对象,并将之push到config controller的 queue 成员里。Task对象除了包含CRD资源对象之外,还包含事件类型(如Add、Update、Delete等),以及处理函数 ChainHandler。ChainHandler支持多个处理函数的串联。
- 启动协程逐一处理CRD资源事件(queue.run),处理方法是调用每个从 queue 中取出的 Task 对象上的 ChainHandler
Task
a) 事件涉及的资源对象
b) 事件类型:Add、Update和Delete
c) Handler:ChainHandler。ChainHandler支持多个处理函数的串联
Service Controller
大体同 Config Controller。
XDS
CDS
cds,即cluster discovery service,是pilot-discovery为Envoy动态提供cluster相关信息的协议。Envoy可以向pilot-discovery的gRPC server发送一个DiscoveryRequest,并将需要获取的配置信息类型(TypeUrl)设置为cds。discovery server,即ads服务的实现类,在收到DiscoveryRequest后,将Abstract Model中保存的相关信息组装成cluster,然后封装在DiscoveryResponse返回给Envoy。
discovery server为了组装出cluster信息,需要从Abstract Model中提取以下两类信息类型;
- 服务注册信息:如从Kubernetes中的服务注册信息转化而来的service
- 通过istioctl提供的配置信息,如DestinationRule
discovery server将这两类信息组装成cluster信息的流程大致如下:
略
EDS
discovery server处理eds类型的DiscoveryRequest的逻辑相对简单,流程如下:
- 根据cluster的名称,把对应Kubernetes中service对象的name和所属的namespace解析出来。使用Kubernetes的client-go库中的SharedIndexInformer获取Kubernetes中的service对象。
- 使用SharedIndexInformer获取 Kubernetes 中的endpoint所有对象(SharedIndexInformer包含了本地缓机制,所以并非每次处理eds类型的DiscoveryRequest都需要从Kubernetes同步大量数据),选择其中name和namespace匹配的endpoint。
- 使用subset中的label(不知道subset中的label代表什么意思的同学,请回忆前面分析cds中关于subcluster构建过程),比如version=v1,再次过滤上步被筛选过的endpoint
- 获取endpoint的ip、端口和可用域(availability zone)等信息。其中的可用域由endpoint对应的pod所运行的node上的两个“著名”label的value构成(中间用”/“分隔),label的key分别为:”failure-domain.beta.kubernetes.io/region”和”failure-domain.beta.kubernetes.io/zone”。
- 根据可用域信息(locality)将endpoint分组,每个locality对应一个LocalityLbEndpoints对象
discovery server在获取endpoint之后,将他们封装在DiscoveryResponse中,将DiscoveryResponse的类型(即TypeUrl)设置为type.googleapis.com/envoy.api.v2.ClusterLoadAssignment,Nonce设置为当前时间(nonce的解释见本文前面部分), 启动单独的协程通过与Envoy建立的双向stream gRPC连接发送给Envoy,发送超时为5秒
1 | // updateCluster is called from the event (or global cache invalidation) to update |
FAQ
对k8s的 list/watch 是什么意思?
k8s提供的基于发布订阅模型的资源变更通知,详见apiserver-list/watch。
Istio 如何处理 k8s 中的服务注册信息,并传递给 Proxy?
k8s 中的服务注册信息一般指 k8s Service 信息,但 Envoy 发起请求时并不走 k8s Service ,而是直接定向到一个 Endpoint,这与 k8s 的思想稍有不同。Istio 会监控 k8s 中的 Services, Endpoint, Node 和 Pod信息,然后自行按照自己的条件将 Endpoint 划分为 subset(Istio 自己的一个概念,k8s Service 的子集)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46// NewController creates a new Kubernetes controller
func NewController(client kubernetes.Interface, options ControllerOptions) *Controller {
log.Infof("Service controller watching namespace %q for service, endpoint, nodes and pods, refresh %d",
options.WatchedNamespace, options.ResyncPeriod)
// Queue requires a time duration for a retry delay after a handler error
out := &Controller{
domainSuffix: options.DomainSuffix,
client: client,
queue: NewQueue(1 * time.Second),
}
out.services = out.createInformer(&v1.Service{}, "Service", options.ResyncPeriod,
func(opts meta_v1.ListOptions) (runtime.Object, error) {
return client.CoreV1().Services(options.WatchedNamespace).List(opts)
},
func(opts meta_v1.ListOptions) (watch.Interface, error) {
return client.CoreV1().Services(options.WatchedNamespace).Watch(opts)
})
out.endpoints = out.createInformer(&v1.Endpoints{}, "Endpoints", options.ResyncPeriod,
func(opts meta_v1.ListOptions) (runtime.Object, error) {
return client.CoreV1().Endpoints(options.WatchedNamespace).List(opts)
},
func(opts meta_v1.ListOptions) (watch.Interface, error) {
return client.CoreV1().Endpoints(options.WatchedNamespace).Watch(opts)
})
out.nodes = out.createInformer(&v1.Node{}, "Node", options.ResyncPeriod,
func(opts meta_v1.ListOptions) (runtime.Object, error) {
return client.CoreV1().Nodes().List(opts)
},
func(opts meta_v1.ListOptions) (watch.Interface, error) {
return client.CoreV1().Nodes().Watch(opts)
})
out.pods = newPodCache(out.createInformer(&v1.Pod{}, "Pod", options.ResyncPeriod,
func(opts meta_v1.ListOptions) (runtime.Object, error) {
return client.CoreV1().Pods(options.WatchedNamespace).List(opts)
},
func(opts meta_v1.ListOptions) (watch.Interface, error) {
return client.CoreV1().Pods(options.WatchedNamespace).Watch(opts)
}))
return out
}