给 AI 选模型就像选员工——聊聊我的 Agent 模型搭配策略
背景
上一篇聊了怎么给 OpenClaw 龙虾 cc 接上图片生成能力。这篇换个话题——聊聊模型选择。
cc 跑在 OpenClaw 上,这个框架支持 37 个以上的模型 provider:Anthropic、OpenAI、OpenRouter、Google、Amazon Bedrock、Ollama……基本上市面上叫得出名字的都能接。接入方式也简单,两步:认证,然后设个默认模型就行。
但”能接”和”怎么接”是两回事。我最终选了两个 provider、三个模型,跑了 5 天之后,有一些挺有意思的发现。
我们的接入方式

我用了两个 provider:
GitHub Copilot — 这是主力。我们用的是 GitHub Copilot 企业版订阅,通过 device flow 登录,直接用订阅里自带的模型额度。好处是不额外花钱,坏处是模型选择受限于 Copilot 提供的范围。目前接了三个模型:
- Claude Opus 4.6 — Anthropic 的旗舰模型
- GPT-5.4 — OpenAI 的最新模型
- GPT-4.1 — 轻量快速,做 alias
fast用
OpenRouter — 用 API key 接入,按量计费,目前只跑了一个模型:小米刚发布的 MiMo v2 Pro。选它主要是因为新模型发布期间限时免费,拿来当日常默认模型,把 Copilot 额度省给重活。
接入过程倒也不是一帆风顺。GitHub Copilot 这个 provider 踩了两个坑:
一个是我们的企业版订阅,token 里带的 proxy endpoint 是 proxy.enterprise.githubcopilot.com,但 OpenClaw 默认配的 baseUrl 是 api.individual.githubcopilot.com。用 enterprise 的 token 去打 individual 的端点,返回了一个我从没见过的 HTTP 状态码——421 Misdirected Request。改个 URL 就好了,但排查花了不少时间。
另一个是 github-copilot 这个 provider 扩展没加到 plugins.allow 列表里,gateway 日志里不停报 “No API provider registered for api: github-copilot”。功能都对,就是忘开一个开关。
5 天的真实数据
好,上数据。以下所有数据来自 cc 的 session transcripts——每次对话 OpenClaw 都会记录模型、token 用量、响应时间等信息,我直接解析了这些 JSONL 文件。
先看用量分布:
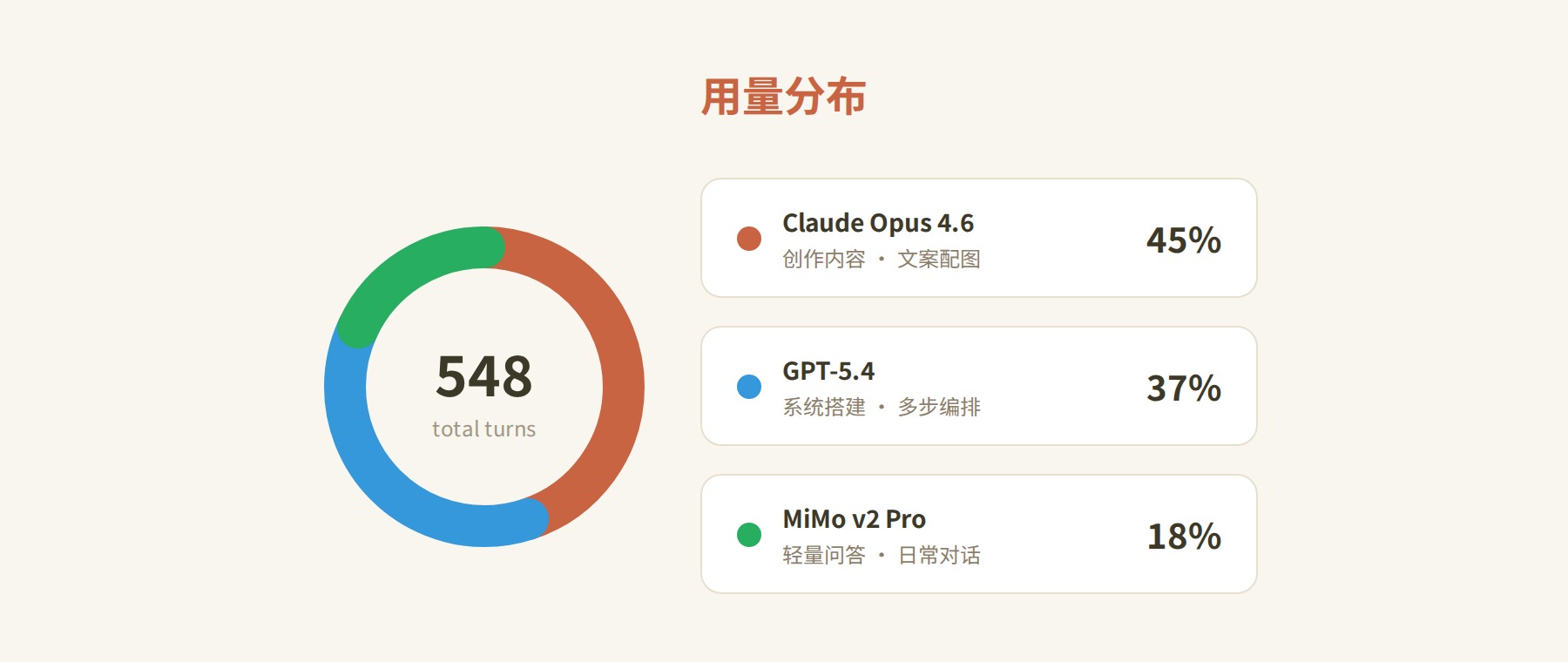
548 个 assistant turns 里,Claude 和 GPT 加起来占了 82%,MiMo 只用了 18%。不是 MiMo 不好,是任务分配决定的——Copilot 的模型免费,当然能用就用。
再看详细对比:

几个值得说的点:
输出量差异很大。 Claude 和 GPT 平均每个 turn 输出 450-530 个 token,MiMo 只有 232。这跟任务类型有关——MiMo 主要处理日常对话和轻量问答,不需要长篇大论;Claude 和 GPT 经常要写文案、改代码、做多步编排,输出自然多。
响应速度差一倍。 Claude 和 GPT 的中位响应时间都在 5-6 秒,MiMo 要 11.5 秒。这个我有点意外——MiMo 走的是 OpenRouter,可能多了一层路由开销。不过作为免费模型,能用就不错了。
工具链深度是硬实力指标。 这个维度比较有意思。Claude 和 GPT 的平均工具链深度在 9-10(最深到 30-35 步),MiMo 只有 5.5。也就是说,遇到需要连续读文件、调 API、改代码、重启服务这种多步编排任务,前两个模型明显更得心应手。
自然形成的分工
用了几天之后,三个模型的分工其实自然就定下来了:
Claude Opus 4.6 → 创意工厂。 主要给我的内容创作 agent 用,写文案、想标题、调语气。它理解意图很准,你说”再朴实一点”它真的能调到位,不会矫枉过正。不过返修率稍高(24%),但这不是模型的问题——创意类任务本来就需要多轮打磨,“图上文字太多""语气再自然点”这种反馈很正常。
GPT-5.4 → 工程担当。 做系统搭建、多步编排、配置调试。返修率只有 7%,基本上给一个指令它就能一条龙搞定。工具链深度经常到 20-30 步,读代码→改文件→重启服务→验证→改文档,一气呵成。
MiMo v2 Pro → 日常助手。 作为默认模型处理轻量级任务,问个问题、查个配置、简单对话。限时免费这一点很关键——省下来的 Copilot 额度可以给重活用。但要是碰到复杂任务,它的工具链深度和输出质量就明显跟不上了。
成本
最后聊聊钱。5 天下来:
- Copilot 模型(Claude + GPT):$0,企业版订阅额度
- MiMo:$0,限时免费推广期
- 总计:$0
作为对比,上篇提到的 FLUX 图片生成,同样 5 天花了大约 18 元人民币(Azure 按量计费)。也就是说,LLM 对话反而没花钱,生图才是真正的开销。
当然 LLM 免费不是常态。MiMo 的免费期过了之后会开始计费,到时候得重新评估。不过 Copilot 企业版订阅里的模型额度确实挺香的——等于白送了 Claude 和 GPT 的使用额度,拿来跑 Agent 非常划算。
小结
模型选择这件事,我的体会是不用追求”一个模型打天下”。不同模型有不同的长处,搭配着用反而效果更好。Claude 写东西有灵性,GPT 执行力强,MiMo 轻量省钱——各司其职就挺好。
OpenClaw 的好处是切换模型很方便,一行命令或者改个配置就行,不用改任何业务代码。所以可以放心大胆地试,找到适合自己的搭配。
不过说到”搭配”,光有 LLM 还不够。后来我发现 cc 在写代码和做 code review 的时候,能力还是有瓶颈。于是我给它装了 GitHub Copilot CLI,让它能调用专门的编码模型来辅助。这个故事,下篇再聊。
moeyui
不是很懂你们程序员