当你入睡,AI 正变得越来越聪明
起因:一次对话里的 33 个 grep
事情要从一条 token 账单说起。
有天我翻 cc 的 session 记录,发现一个调试任务用了 33 次 exec 调用—全是 grep、sed、cat 一条条串起来的。提取 5 个 CSS 属性,它调了 5 次 grep。每改一行代码,它就 grep 一次确认改对了。
这些调用每一个都不贵,但堆在一起,token 消耗很可观。更关键的是,这不是偶发—它是一种思维模式:不确定就试一下、试完再看一下、看完再试一下。
我跟 cc 说:你能不能自己 review 自己的历史记录,找出这些浪费?
cc 说:好。
然后我说:不是现在一次,是定期。
设计:一个每 6 小时跑一次的自省任务
OpenClaw 有个 cron 系统,可以定时触发 Agent 任务。我给 cc 创建了一个叫 session-review-learn 的定时任务:
- 频率:每 6 小时
- 做什么:读最近 3 天的 session 记录,扫描所有工具调用,找出浪费模式
- 输出:把发现写进
memory/tool-call-review.md,如果发现新的反模式就更新AGENTS.md的规则 - 汇报:每次跑完给我发一份摘要
同时我让 cc 把这套逻辑写成了一个 Skill(learn-from-history),这样除了定时跑,我随时说一句”learn”它也能手动触发。
整个设计的核心理念很简单:让 AI 自己审计自己,把经验沉淀成规则,让下一次会话自动继承。
第一轮数据:浪费率 34%
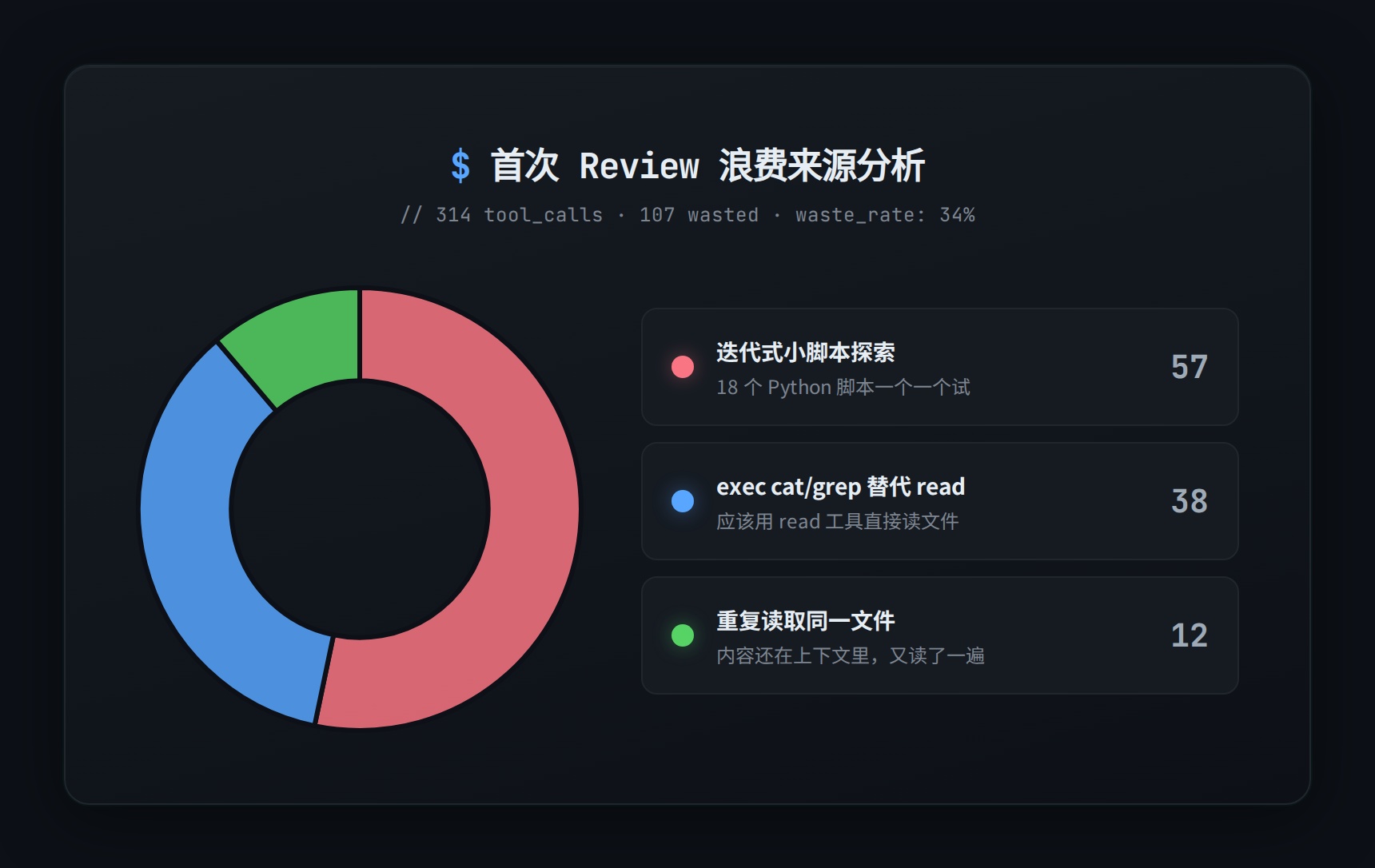
第一次有效的 review 跑出来,数字有点触目惊心:
- 4 个 session,314 次工具调用
- 浪费率 34%—大约 100 次调用是不必要的
- 最大的浪费来源:用 18 个小 Python 脚本一点一点试,本来写一个就够了
- 38 次
exec cat/grep本该用read工具直接读文件 - 12 次重复读取同一个文件—内容还在上下文里呢,又读了一遍
cc 自己也发现了这些问题,往 AGENTS.md 加了两条新规则:
- 不要重复读文件。如果刚读过,内容还在上下文里,别再读一遍。
- 不要盲目重试失败的命令。失败两次就停下来查原因。
趋势:从 34% 到 7%
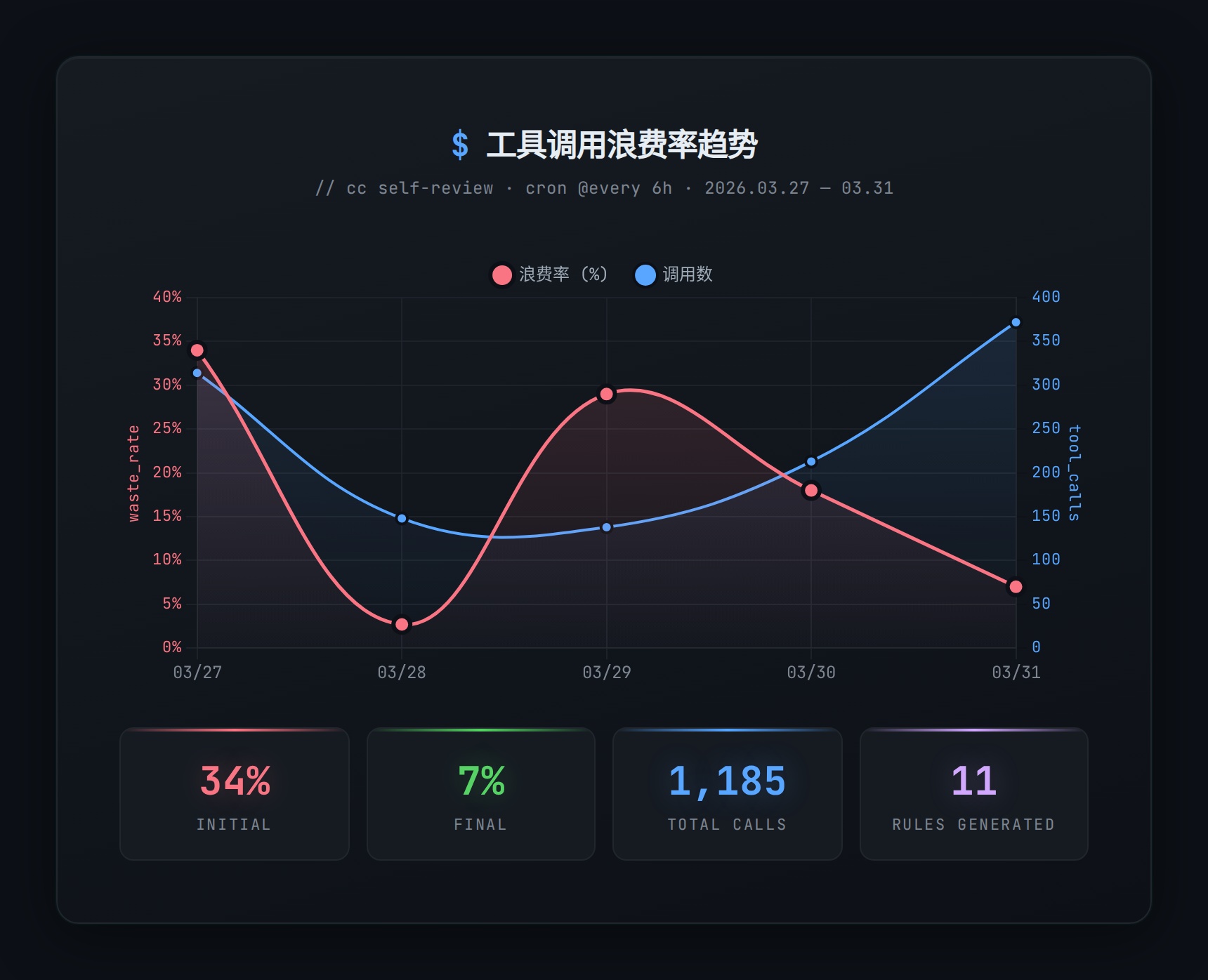
接下来的几天,cron 每 6 小时跑一次,浪费率的变化是这样的:
| 时间 | Sessions | 调用数 | 浪费率 | 新发现 |
|---|---|---|---|---|
| 3/27 | 4 | 314 | 34% | 迭代式探索、重复读文件 |
| 3/28 | 6 | 148 | 2.7% | 无(简单 session 很干净) |
| 3/29 | 7 | 138 | 29% | exec 链过长(最长 136 次) |
| 3/30 | 10 | 213 | 18% | 链式 grep 仍是主要浪费 |
| 3/31 | 10 | 372 | 7% | 无新模式—规则够了,问题在执行 |
波动很大,但趋势是向下的。有意思的是,cc 自己总结出了一个规律:短 session 基本不浪费,浪费集中在长时间 debug 的 session 里。
一旦进入”改一行 → 重启 → 看日志 → 再改一行”的循环,纪律就崩了。这跟人类程序员的表现几乎一模一样—冷静的时候知道该写个脚本,焦躁的时候就开始一条条敲。
它给自己写了 11 条规则
经过多轮 review,cc 在 AGENTS.md 里积累了一套 “Tool Call Discipline” 规则:
- 不要链式 grep—读一次文件,脑子里解析
- 不要每次 edit 后都验证—信任 exit code
- 不要 find → ls → grep 三连—一条命令搞定
- 批量编辑用脚本,不要一条条 sed
- 用
read工具,别用cat/grep/head - 不要重复读同一个文件
- 不要盲目重试
- 不要猜 API 参数—先读文档
- exec 链不超过 10 条
- 不要 patch → restart → grep 循环—先写测试
- 不要反复读生成的图片确认它存在
每一条背后都有真实的 session 记录作为证据。不是我教的,是它自己从历史里挖出来的。

翻车:exec 审批和 cron 超时
故事讲到这里好像很完美,但后半段翻车了。
OpenClaw 的安全模型要求 exec 命令需要人工审批。cron 任务跑在隔离 session 里,没有交互式客户端,审批通不过。
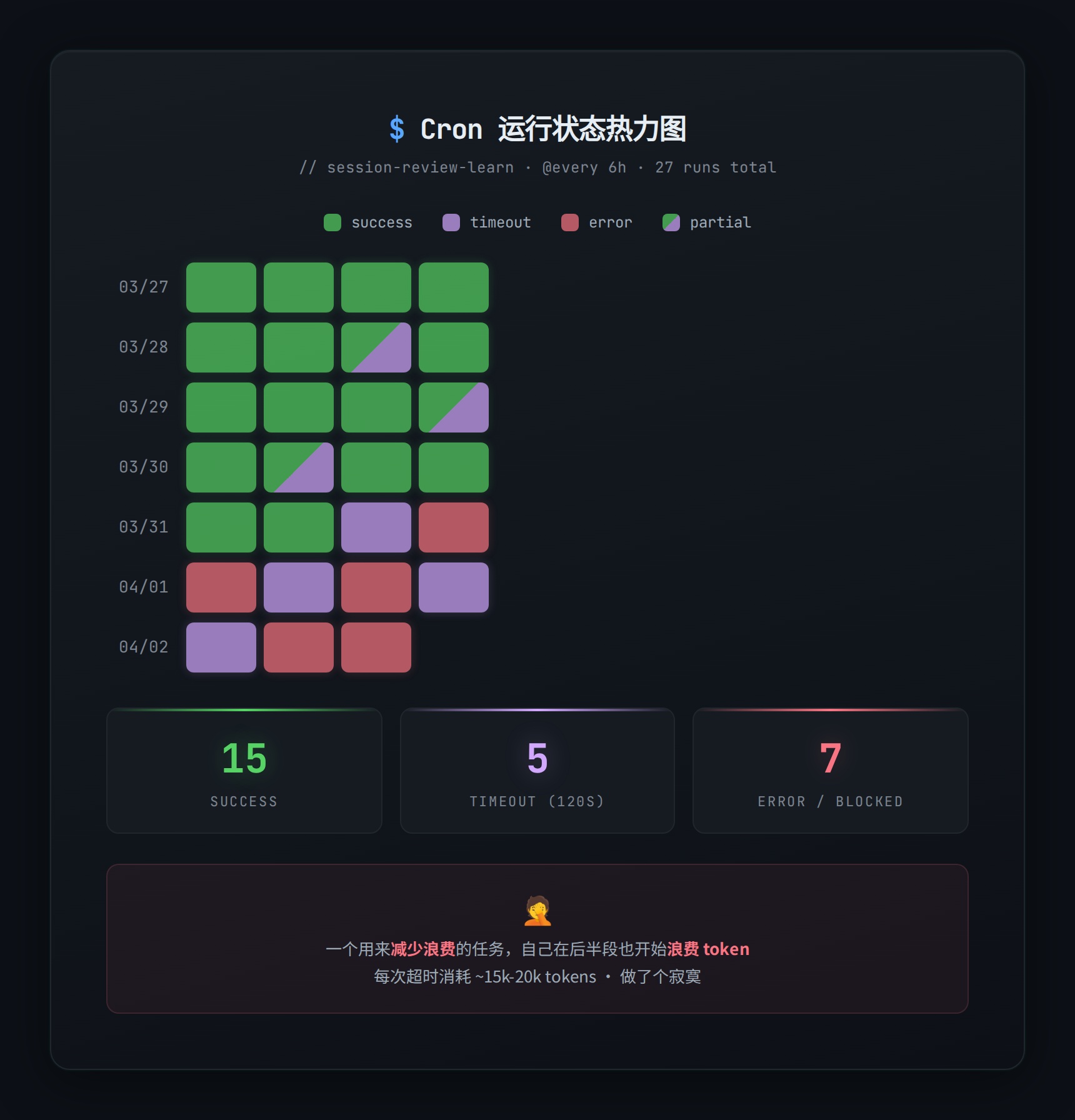
于是从 4 月 1 日开始,cron 的运行记录变成了这样:
❌ cron: job execution timed out
❌ Exec approval unavailable, skipped
❌ cron: job execution timed out
❌ Only this cron session visible, no data
❌ cron: job execution timed out27 次运行,全部标记为 error。其中大约一半是超时(120 秒),另一半是”完成了但没法发送结果”(delivery channel 没配好)。
cc 在好几次 review 里都建议我:“要么给 cron session 开 exec 白名单,要么把 skill 改成只用 sessions API 不用 exec。”
说实话挺讽刺的—一个用来减少浪费的任务,自己也在浪费 token。每次超时的 cron 运行至少消耗 15k-20k token 做了个寂寞。
真正学到了什么
撇开数字,这个实验让我对”AI 自我改进”有了更具体的认识:
能学到什么: 它确实能从历史中提取模式,把散落在各个 session 里的教训总结成规则,写进 AGENTS.md 让后续 session 继承。从 34% 到 7%,不是幻觉。
学不到什么: 规则写了不代表能执行。cc 自己说”所有浪费都已经被规则覆盖了,问题不是缺规则,是执行”。当 debug 进入焦躁状态,它跟人一样会忘记自己写的规则。
基础设施很重要: 想法很好(定时自省),但 exec 审批、超时限制、delivery channel 配置这些运维层面的问题,差点让整个机制废掉。AI 的自我改进不只是 prompt 和模型的事,脚手架得配套。
短 session 天生干净: 浪费集中在长 debug session 里。也许比起教 AI 自律,更好的策略是—拆短任务、用 sub-agent、别让一个 session 跑太久。
下一步
这个 cron 还在跑,虽然最近全在报错。我计划做两件事:
- 把 skill 改成纯 API 调用,不依赖 exec,彻底解决审批问题
- 加一个”如果连续 3 次失败就自动 disable”的机制,别空烧 token
cc 问我:“要不要重构 skill?”
要的。不过这本身也是一个值得记录的教训—系统设计的第一版永远不是最终版,哪怕设计者是 AI。
moeyui
不是很懂你们程序员